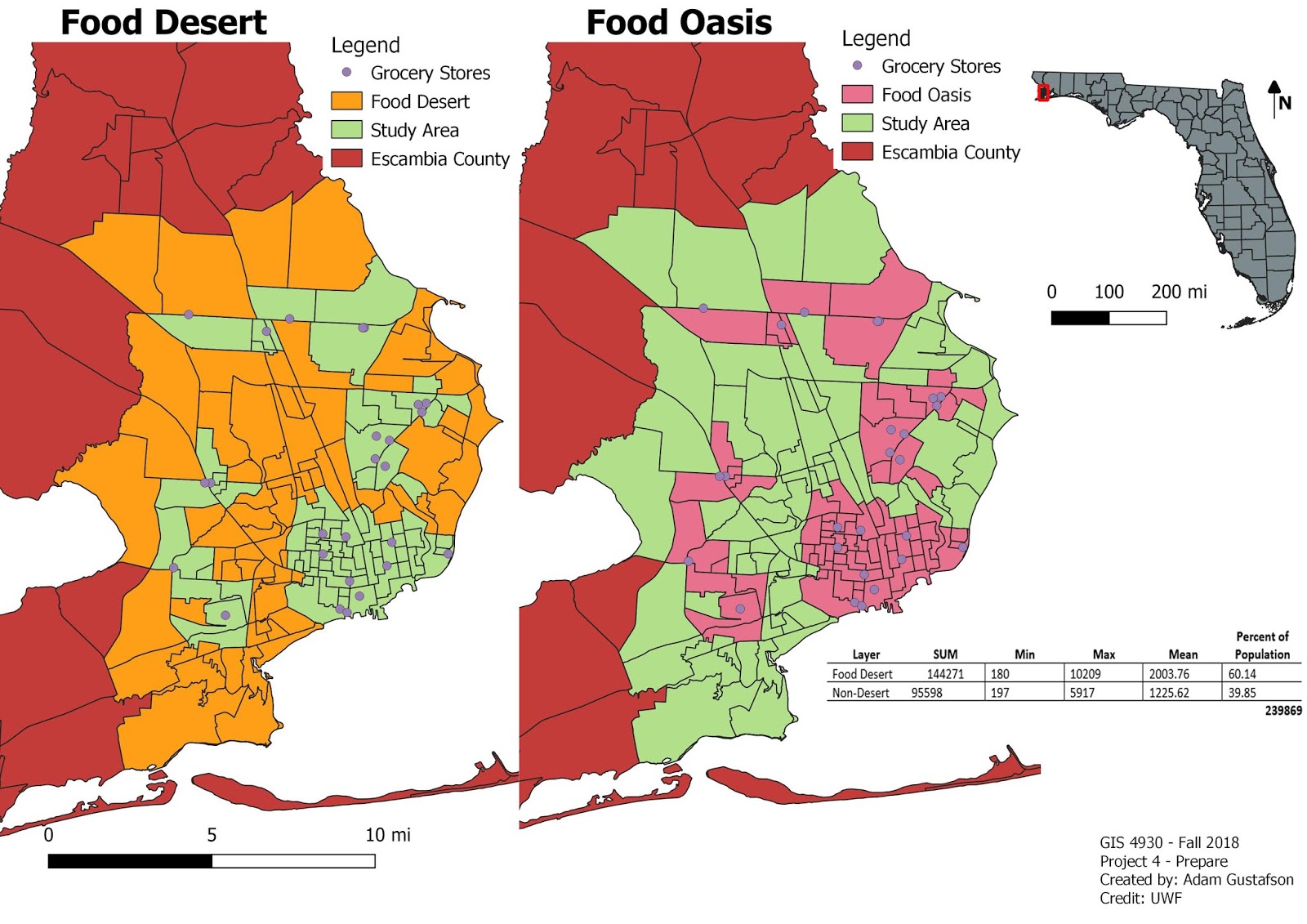
For this weeks portion of Project 4 we were tasked with taking the food desert and grocery store shape file data we created last week and uploading them into two open source web map making programs, Mapbox and Leaflet.
Using mapbox I was able to design a layout with a graduated symbology split into five classes based on fooddesert.shp's pop2000 field.
Using the quickstart guide, and the project procedures I was able to create a marker displaying 2 text lines, a circle in a food oasis area, and a 4 coordinate polygon in a food desert area.
Some problems that I ran into over the course of this weeks project include: not being able to locate the correct mapbox to leaflet link required to transfer the maps tileset. Therefore my fooddeserts and grocerystores files are not displayed on my leaflet map.

Link to mapbox map displaying tileset